Michael Reiss, a professor of science education at University College London and an Anglican Priest, suggests that “we need to rethink the way we teach evolution” largely because conventional approaches can be unduly confrontational and “force religious children to choose between their faith and evolution” or to result in students who”refuse to engage with a lesson.” He suggests that a better strategy would be akin to those use to teach a range of “sensitive” subjects “such as sex, pornography, ethnicity, religion, death studies, terrorism, and others” and could “help some students to consider evolution as a possibility who would otherwise not do so.” [link to his original essay and a previous post on teaching evolution: Go ahead and teach the controversy].
There is no doubt that an effective teacher attempts to present materials sensitively; it is the rare person who will listen to someone who “teaches” ideas in a hostile, alienating, or condescending manner. That said, it can be difficult to avoid the disturbing implications of scientific ideas, implications that can be a barrier to their acceptance. The scientific conclusion that males and females are different but basically the same can upset people on various sides of the theo-political spectrum.
In point of fact an effective teacher, a teacher who encourages students to question their long held, or perhaps better put, familial or community beliefs, can cause serious social push-back – Trouble with a capital T. It is difficult to imagine a more effective teacher than Socrates (~470-399 BCE). Socrates “was found guilty of ‘impiety’ and ‘corrupting the young’, sentenced to death” in part because he was an effective teacher (see Socrates was guilty as charged). In a religious and political context, challenging accepted Truths (again with a capital T) can be a crime. In Socrates’ case”Athenians probably genuinely felt that undesirables in their midst had offended Zeus and his fellow deities,” and that, “Socrates, an unconventional thinker who questioned the legitimacy and authority of many of the accepted gods, fitted that bill.”
So we need to ask of scientists and science instructors, does the presentation of a scientific, that is, a naturalistic and non-supernatural, perspective in and of itself represent an insensitivity to those with a super-natural belief system. Here it is worth noting a point made by the philosopher John Gray, that such systems extend beyond those based on a belief in god(s); they include those who believe, with apocalyptic certainty, in any of a number of Truths, ranging from the triumph of a master race, the forced sterilization of the unfit, the dictatorship of the proletariat, to history’s end in a glorious capitalist and technological utopia. Is a science or science instruction that is “sensitive” to, that is, uncritical of or upsetting to those who hold such beliefs, possible?
My original impression is that one’s answer to this question is likely to be determined by whether one considers science a path to Truth, with a purposeful capital T, or rather that the goal of scientists is to build a working understanding of the world around and within us. Working scientists, and particularly biologists who must daily confront the implications of apparently un-intelligent designed organisms (due to ways evolution works) are well aware that absolute certainty is counterproductive. Nevertheless, the proven explanatory and technological power of the scientific enterprise cannot help but reinforce the strong impression that there is some deep link between scientific ideas and the way the world really works. And while some scientists have advocated unscientific speculations (think multiverses and cosmic consciousness), the truth, with a small t, of scientific thinking is all around us.
Photograph of the Milky Way by Tim Carl photography, used by permission
A science-based appreciation of the unimaginable size and age of the universe, taken together with compelling evidence for the relatively recent appearance of humans (Homo sapiens from their metazoan, vertebrate, tetrapod, mammalian, and primate ancestors) cannot help but impact our thinking as to our significance in the grand scheme of things (assuming that there is such a, possibly ineffable, plan)(1). The demonstrably random processes of mutation and the generally ruthless logic by which organisms survive, reproduce, and evolve, can lead even the most optimistic to question whether existence has any real meaning.
Consider, as an example, the potential implications of the progress being made in terms of computer-based artificial intelligence, together with advances in our understanding of the molecular and cellular connection networks that underlie human consciousness and self-consciousness. It is a small step to conclude, implicitly or explicitly, that humans (and all other organisms with a nervous system) are “just” wet machines that can (and perhaps should) be controlled and manipulated. The premise, the “self-evident truth”, that humans should be valued in and of themselves, and that their rights should be respected (2) is eroded by the ability of machines to perform what were previously thought to be exclusively human behaviors.
Humans and their societies have, after all, been around for only a few tens of thousands of years. During this time, human social organizations have passed from small wandering bands influenced by evolutionary kin and group selection processes to produce various social systems, ranging from more or less functional democracies, pseudo-democracies (including our own growing plutocracy), dictatorships, some religion-based, and totalitarian police states. Whether humans have a long term future (compared to the millions of years that dinosaurs dominated life on Earth) remains to be seen – although we can be reasonably sure that the Earth, and many of its non-human inhabitants, will continue to exist and evolve for millions to billions of years, at least until the Sun explodes.
So how do we teach scientific conclusions and their empirical foundations, which combine to argue that science represents how the world really works, without upsetting the most religiously and politically fanatical among us? Those who most vehemently reject scientific thinking because they are the most threatened by its apparently unavoidable implications. The answer is open to debate, but to my mind it involves teaching students (and encouraging the public) to distinguish empirically-based, and so inherently limited observations and the logical, coherent, and testable scientific models they give rise to from unquestionable TRUTH- and revelation-based belief systems. Perhaps we need to focus explicitly on the value of science rather than its “Truth”. To reinforce what science is ultimately for; what justifies society’s support for it, namely to help reduce human suffering and (where it makes sense) to enhance the human experience, goals anchored in the perhaps logically unjustifiable, but nevertheless essential acceptance of the inherent value of each person.
Apologies to “Good Omens”
For example, “We hold these truths to be self-evident, that all men are created equal, that they are endowed by their creator with certain unalienable rights, that among these are life, liberty and the pursuit of happiness.”
Please note, given the move from PLoS some of the links in the posts may be broken; some minor editing in process. All by Mike Klymkowsky unless otherwise noted
Embryogenesis is based on a framework of social (cell-cell) interactions, initial and early asymmetries, and cascading cell-cell signaling and gene regulatory networks (DEVO posts one, two, & three). The result is the generation of embryonic axes, germ layers (ectoderm, mesoderm, endoderm), various organs and tissues (brains, limbs, kidneys, hearts, and such) and their characteristic cell types, their patterning, and their coordination into a functioning organism. It is well established that all animals share a common ancestor (hundreds of millions of years ago) and that a number of molecularmodules were already present in that common ancestor.
At the same time evolutionary processes are, and need to be, flexible enough to generate the great diversity of organisms, with their various adaptations to particular life-styles. The extent of both conservation and flexibility (new genes, new mechanisms) in developmental systems is, however, surprising. Perhaps the most striking evidence for the depth of this conservation was supplied by the discovery of the organization of the Hox gene cluster in the fruit fly Drosophila and in the mouse (and other vertebrates). In both, the Hox genes are arranged and expressed in a common genomic and expression patterns. But as noted by Denis Duboule (2007) Hox gene organization is often presented in textbooks in a distorted manner (↓).
The Hox gene clusters of vertebrates are compact, but are split, disorganized, and even “atomized” in other types of organisms. Similarly, processes that might appear foundational, such as the role of the Bicoid gradient in the early fruit fly embryo (a standard topic in developmental biology textbooks), is in fact restricted to a small subset of flies (Stauber et al., 1999). New genes can be generated through well defined processes, such as gene duplication and divergence, or they can arise de novo out of sequence noise (Carvunis et al., 2012; Zhao et al., 2014 – see Van Oss & Carvunis 2019. De novo gene birth). Comparative genomic analyses can reveal the origins of specific adaptations (see Stauber et al., 1999).The result is that organisms as closely related to each other as the great apes (including humans) have significant species-specific genetic differences (see Florio et al., 2018; McLean et al., 2011; Sassa, 2013 and references therein) as well as common molecular and cellular mechanisms.
A universal (?) feature of developing systems – gradients and non-linear responses: There is a predilection to find (and even more to teach) simple mechanisms that attempt to explain everything (witness the distortion of the Hox cluster, above) – a form of physics “theory of everything” envy.But the historic nature, evolutionary plasticity, and need for regulatory robustness generally lead to complex and idiosyncratic responses in biological systems.Biological systems are not “intelligently designed” but rather cobbled together over time through noise (mutation) and selection (Jacob, 1977)(see blog post).
That said, acommon (universal?) developmental process appears to be the transformation of asymmetries into unambiguous cell fate decisions. Such responses are based on threshold events controlled by a range of molecular behaviors, leading to discrete gene expression states. We can approach the question of how such decisions are made from both an abstract and a concrete perspective. Here I outline my initial approach – I plan to introduce organism specific details as needed.I start with the response to a signaling gradient, such as that found in many developmental systems, including the vertebrate spinal cord (top image Briscoe and Small, 2015) and the early Drosophila embryo (Lipshitz, 2009)(↓).
We begin with a gradient in the concentration of a “regulatory molecule” (the regulator).The shape of the gradient depends upon the sites and rates of synthesis, transport away from these sites, and turnover (degradation and/or inactivation). We assume, for simplicity’s sake, that the regulator directly controls the expression of target gene(s). Such a molecule binds in a sequence specific manner to regulatory sites, there could be a few or hundreds, and lead to the activation (or inhibition) of the DNA-dependent, RNA polymerase (polymerase), which generates RNA molecules complementary to one strand of the DNA. Both the binding of the regulator and the polymerase are stochastic processes, driven by diffusion, molecular collisions, and binding interactions.(1)
Let us now consider the response of target gene(s) as a function of cell position within the gradient. We might (naively) expect that the rate of target gene expression would be a simple function of regulator concentration. For an activator, where the gradient is high, target gene expression would be high, where the gradient concentration is low, target gene expression would be low – in between, target gene expression would be proportional to regulator concentration.But generally we find something different, we find that the expression of target genes is non-uniform, that is there are thresholds in the gradient: on one side of the threshold concentration the target gene is completely off (not expressed), while on the other side of the threshold concentration, the target gene is fully on (maximally expressed).The target gene responds as if it is controlled by an on-off switch. How do we understand the molecular basis for this behavior?
Distinct mechanisms are used in different systems, but we will consider a system from the gastrointestinal bacteria E. coli that students may already be familiar with; these are the genes that enable E. coli to digest the mammalian milk sugar lactose.They encode a protein needed to importlactose into a bacterial cell and an enzyme needed to break lactose down so that it can be metabolized.Given the energetic cost to synthesize these proteins, it is in the bacterium’s adaptive self interest to synthesize them only when lactose is present at sufficient concentrations in their environment.The response is functionally similar to that associated with quorum sensing, which is also governed by threshold effects. Similarly cells respond to the concentration of regulator molecules (in a gradient) by turning on specific genes in specific domains, rather than uniformly.
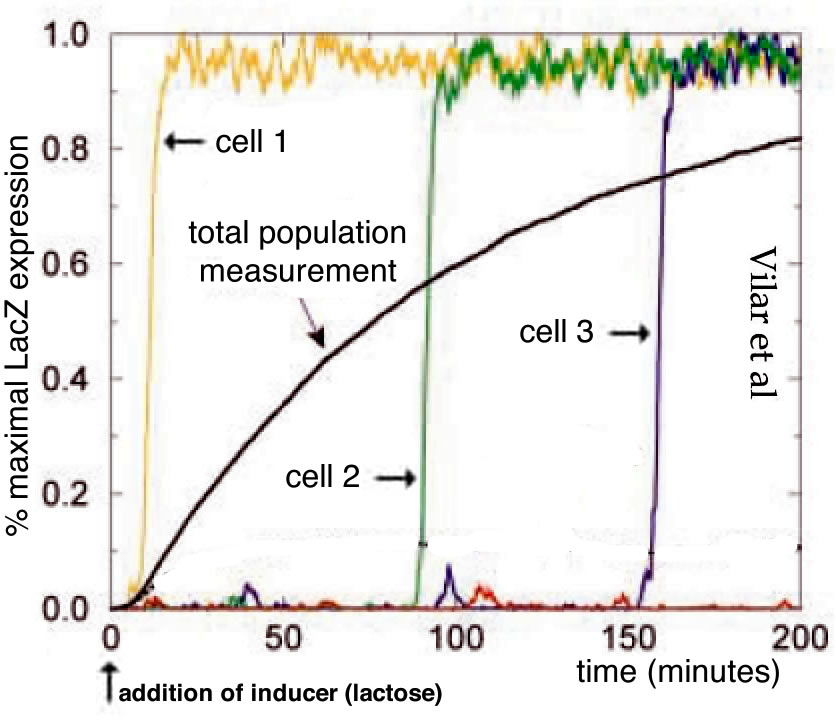
Now let us look in a little more detail at the behavior of the lactose utilization system in E. coli following an analysis by Vilar et al (2003)(2).At an extracellular lactose concentration below the threshold, the system is off.If we increase the extracellular lactose concentration above threshold the system turns on, the lactose permease and β-galactosidase proteins are made and lactose can enter the cell and be broken down to produce metabolizable sugars.By looking at individual cells, we find that they transition, apparently stochastically from off to on (→), but whether they stay on depends upon the extracellular lactose concentration. We can define a concentration, the maintenance concentration, below the threshold, at which “on” cells will remain on, while “off” cells will remain off.
The circuitry of the lactose system is well defined(Jacob and Monod, 1961; Lewis, 2013; Monod et al., 1963)(↓).The lacI gene encodes the lactose operon repressor protein and it is expressed constituately at a low level; it binds to sequences in the lac operon and inhibits transcription.The lac operon itself contains three genes whose expression is regulated by a constituatively active promoter.LacY encodes the permease while the lacZ encodes β-galactosidase.β-galactosidase has two functions: it catalyzes the reaction that transforms lactose into allolactone and it cleaves lactose into the metabolically useful sugars glucose and galactose. Allolactone is an allosteric modulator of the Lac repressor protein; if allolactone is present, it binds to lac epressor proteins and inactivates them, allowing lac operon expression.
The cell normally contains only ~10 lactose repressor proteins. Periodically (stochastically), even in the absence of lactose, and so its derivative allolactone, the lac operon promoter region is free of repressor proteins, and a lactose operon is briefly expressed – a few LacY and LacZpolypeptides are synthesized (↓).This noisy leakiness in the regulation of the lac operon allows the cell to respond if lactose happens to be present – some lactose molecules enter the cell through the permease, are converted to allolactone by β-galactosidase.Allolactone is an allosteric effector of the lac repressor; when present it binds to and inactivates the lac repressor protein so that it no longer binds to its target sequences (the operator or “O” sites).In the absence of repressor binding, the lac operon is expressed.If lactose is not present, the lac operon is inhibited and lacY and LacZ disappear from the cell by turnover or growth associated dilution.
The question of how the threshold concentration for various signal-regulated decisions is set often involves homeostatic processes that oppose the signaling response. The binding and activation of regulators can involve cooperative interactions between molecular components and both positive and negative feedback effects.
In the case of patterning a tissue, in terms of regional responses to a signaling gradient, there can be multiple regulatory thresholds for different genes, as well as indirect effects, where the initiation of gene expression of one set of target genes impacts the sensitive expression of subsequent sets of genes.One widely noted mechanism, known as reaction-diffusion, was suggested by the English mathematician Alan Turing (see Kondo and Miura, 2010) – it postulates a two component system. One component is an activator of gene expression, which in addition to its own various targets, positively regulates its own expression. The second component is a repressor of the first.Both of these two regulator molecules are released by the signaling cell or cells; the repressor diffuses away from the source faster than the activator does.The result can be a domain of target gene expression (where the concentration of activator is sufficient to escape repression), surrounded by a zone in which expression is inhibited (where repressor concentration is sufficient to inhibit the activator).Depending upon the geometry of the system, this can result in discrete regions (dots or stripes) of primary target gene expression (see Sheth et al., 2012).In real systems there are often multiple gradients present; their relative orientations can produce a range of patterns.
The point of all of this, is that when we approach a particular system – we need to consider the mechanisms involved.Typically they are selected to produce desired phenotypes, but also to be robust in the sense that they need to produce the same patterns even if the system in which they occur is subject to perturbations, such as embryo/tissue size (due to differences in cell division / growth rates) and temperature and other environmental variables.
note: figures returned – updated 13 November 2020.
Footnotes:
While stochastic (random) these processes can still be predictable.A classic example involves the decay of an unstable isotope (atom), which is predictable at the population level, but unpredictable at the level of an individual atom.Similarly, in biological systems, the binding and unbinding of molecules to one another, such as a protein transcription regulator to its target DNA sequence is stochastic but can be predictable in a large enough population.
Briscoe & Small (2015). Morphogen rules: design principles of gradient-mediated embryo patterning. Development 142, 3996-4009.
Carvunis et al (2012). Proto-genes and de novo gene birth. Nature 487, 370.
Duboule (2007). The rise and fall of Hox gene clusters. Development 134, 2549-2560.
Florio et al (2018). Evolution and cell-type specificity of human-specific genes preferentially expressed in progenitors of fetal neocortex. eLife 7.
Jacob (1977). Evolution and tinkering. Science 196, 1161-1166.
Jacob & Monod (1961). Genetic regulatory mechanisms in the synthesis of proteins. Journal of Molecular Biology 3, 318-356.
Kondo & Miura (2010). Reaction-diffusion model as a framework for understanding biological pattern formation. Science 329, 1616-1620.
Lewis (2013). Allostery and the lac Operon. Journal of Molecular Biology 425, 2309-2316.
Lipshitz (2009). Follow the mRNA: a new model for Bicoid gradient formation. Nature Reviews Molecular Cell Biology 10, 509.
McLean et al (2011). Human-specific loss of regulatory DNA and the evolution of human-specific traits. Nature 471, 216-219.
Monod Changeux & Jacob (1963). Allosteric proteins and cellular control systems. Journal of Molecular Biology 6, 306-329.
Sassa (2013). The role of human-specific gene duplications during brain development and evolution. Journal of Neurogenetics 27, 86-96.
Sheth et al (2012). Hox genes regulate digit patterning by controlling the wavelength of a Turing-type mechanism. Science 338, 1476-1480.
Stauber et al (1999). The anterior determinant bicoid of Drosophila is a derived Hox class 3 gene. Proceedings of the National Academy of Sciences 96, 3786-3789.
Vilar et al (2003). Modeling network dynamics: the lac operon, a case study. J Cell Biol 161, 471-476.
[21st Century DEVO-3] Embryonic development is the process by which a fertilized egg becomes an independent organism, an organism capable of producing functional gametes, and so a new generation. In an animal, this process generally involves substantial growth and multiple rounds of mitotic cell division; the resulting organism, a clone of the single-celled zygote, contains hundreds, thousands, millions, billions, or trillions of cells [link]. These dividing, migrating, differentiating, and sometimes dying cells that interact to form the adult and its various tissues and organ systems. The various cell types generated can be characterized by the genes that they express, the shapes they assume, the behaviors that they display, and how they interact with neighboring and distant cells (1). Based on first principles, one could imagine (at least) two general mechanisms that could lead to differences in gene expression between cells. The first would be that different cells contain different genes while the other is that while all cells contain all genes, which genes are expressed in a particular cell varies,it is regulated by molecular processes that determine when, where, and to what the levels particular genes are expressed (2). Turns out, there are examples of both processes among the animals, although the latter is much more common.
The process of discarding genomic DNA in somatic cells is known as chromatin diminution. During the development of the soma, but not the germ line, regions of the genome are lost. In the germ line, for hopefully obvious reasons, the full genome is retained. The end result is that somatic cells contain different subsets of genes and non-coding DNA compared to the full genome. The classic case of chromosome diminution was described in the parasitic nematode of horses, now named Parascaris univalens (originally Ascaris megalocephala) by Theodore Boveri in 1887 (reviewed in Streit and Davis, 2016)[pdf link]. Based on its occurrence in a range of distinct animal lineages, chromatin diminution appears to be an emergent rather than an ancestral trait, that is, a trait present in the common ancestor of the animals.
While, as expected for an emergent trait, the particular mechanism of chromatin diminution appears to vary between different organisms: the best characterized example occurs in Parascaris. In the somatic cell lineages in which chromatin diminution occurs, double-stranded breaks are made inchromosomal DNA molecules, and teleomeric sequences are added to ends of the resulting DNA molecules (↓).
You may have learned that chromosomes interact with spindle microtubules through a localized regions on the chromosomes, known as centromeres. Centromeres are identified through their association with proteins that form the kinetochore, which is a structure that mediates interactions between condensed chromosomes and mitotic (and meiotic) spindle microtubules. While many organisms have a discrete spot-like (localized) centromere, in many nematodes centromere-binding proteins are found distributed along the length of the chromosomes, a situation known as a holocentric centromere.At higher resolution it appears that centromere components are preferentially associated with euchromatic, that is, molecularly accessible chromosomal regions, which are (typically) the regions where most expressed genes are located.Centromere components are largely excluded from heterochromatic (condensed and molecularly inaccessible) chromosomal regions. After chromosome fragmentation, those DNA fragments associated with centromere components can interact with the spindle microtubules and are accurately segregated to daughter cells during mitosis, while those, primarily heterochromatic fragments (without associated centromeric components) are degraded and lost. In contrast the integrity of the genome is maintained in those cells that come to form the germ line, the cells that can undergo meiosis to produce gametes.Looking forward to the reprogramming of somatic cells (the process of producing what are known as induced pluripotent stem cells – iPSCs), one prediction is that it should not be possible to reprogram a somatic cell that has undergone chromatin diminution to form a functional germ line cell – you should be able to explain why, or what would have to be the case for such reprogramming to be successful.
The origins of cellular asymmetries:Clearly, there must be differences between the cells that undergo chromatin diminution and those that do not; at the very least the nuclease(s) that cuts the DNA during chromatin diminution will need to be active in somatic cells and inactive in germ line cells, or it may simply not be present – the genes that encode it are not expressed in germ line cells. We can presume that similar cytoplasmic differences play a role in the differential regulation of gene expression in different cell types during the development of organisms in which the genome remains intact in somatic cells. So how might such asymmetries arise?There are three potential, but certainly not mutually exclusive, mechanisms that can lead to cellular/cytoplasmic asymmetries: they can be inherited based on pre-existing asymmetries in the parental cell, they could emerge based on asymmetries in the signaling environments occupied by the two daughters, or they could arise from stochastic fluctuations in gene expression (see Chen et al., 2016; Neumüller and Knoblich, 2009).
One example of how an asymmetry can be established occurs in the free-living nematode Caenorhabditiselegans, where the site of sperm fusion with the egg leads to the recruitment and assembly of proteins around the site of sperm entry, the future posterior side of the embryo.After male and female pronuclei fuse, mitosis begins and cytokinesis divides the zygote into two cells; the asymmetry initiated by sperm entry leads to an asymmetric division (↑); the anterior AB blastomere is larger, and molecularly distinct from the smaller posterior P1 blastomere.These differences set off a regulatory cascade, in which the genes expressed at one stage influence those expressed subsequently, and so influence subsequent cell divisions / cell fate decisions.
Other organisms use different mechanisms to generate cellular asymmetries. In organisms that have external fertilization, such as the clawed frog Xenopus, development proceeds rapidly once fertilization occurs. The egg is large, since in contains all of the materials necessary for the formation until the time that the embryo can feed itself. The early embryo is immotile and vulnerable to predation, so early development in such species tends to be rapid, and based on materials supplied by the mother (leading to maternal effects on subsequent development).In such cases, the initial asymmetry is built into the organization of the oocyte.
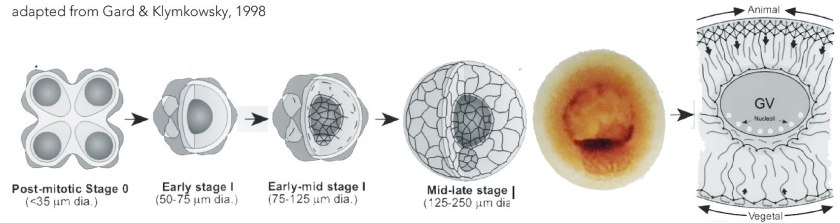
Formed through a mitotic division the primary oocyte enters meiotic prophase I, during which it undergoes a period of growth. Maternal and paternal chromosomes align (syngamy) and undergo crossing-over (recombination).The oocyte contains a single centrosome, a cytoplasmic structure that surrounds the centrioles of the oocyte’s inherited mitotic spindle pole. Cytoplasmic components become organized around the pole and then move from the pole toward the cell cortex (↓ image from Gard and Klymkowsky, 1998); this movement defines an “animal-vegetal” axisof the oocyte, which upon fertilization will play a role in generating the head-tail (anterior-posterior) and back-belly (dorsal-ventral) axes of the embryo and adult.
The primary oocyte remains in prophase I throughout oogenesis. The asymmetry of the oocyte becomes visible through the development of a pigmented animal hemisphere, largely non-pigmented vegetal hemisphere, and an large (~300 um diameter) and off-centered nucleus (known as the germinal vesicle or GV)(3).Messenger RNA molecules, encoding different polypeptides, are differentially localized to the animal and vegetal regions of the late stage oocyte. The translation of these mRNAs is regulated by factors activated by subsequent developmental events, leading to molecular asymmetries between embryonic cells derived from the animal and vegetal regions of the oocyte.In preparation for fertilization, the oocyte resumes active meiosis,leading to the formation of two polar bodies and the secondary oocyte, the egg. Fertilization occurs within the pigmented animal hemisphere; the site of sperm entry (↓) produces a second driver of asymmetry, in addition to the animal-vegetal axis, albeit through a mechanism distinct from that used in C. elegans (De Domenico et al., 2015).
Asymmetries in oocytes and eggs, and sperm entry points are not always the primary drivers of subsequent embryonic differentiation.In the mouse, and other placental mammals, including humans, embryonic development occurs within, and is supported by and dependent upon the mother.The mouse (mammalian) egg appears grossly symmetric, and sperm entry itself does not appear to impose an asymmetry.Rather, as the zygote divides, the first cells formed appear to be similar to one another. As cell division continue, however, some cells find themselves on the surface while others are located within the interior of the forming ball of cells, or morula (↓).
These two cellpopulations are exposed to different environments, environments that influence patterns of gene expression. The cells on the surface differentiate to form the trophectoderm, which in turn differentiates into extra-embryonic placental tissues, the interface between mother and developing embryo.The internal cells becomes the inner cell mass, which differentiate to form the embryo proper, the future mouse (or human). Early on inner cell mass cells appear similar to one another, but they also experience different environments, leading to emerging asymmetries associated with the activation of different signaling systems, the expression of different sets of genes, and difference in behavior – they begin the process of differentiating into distinct cell lineages and types forming, as embryogenesis continues, different tissues and organs.
The response of a particular cell to a particular environment will depend upon the signaling molecules present, typically expressed by neighboring cells, the signaling molecule receptors expressed by the cell itself, and how the binding of signaling molecules to receptors alters receptor activity or stability. For example, an activated receptor can activate (or inhibit) a transcription factor protein that could influence the expression of a subset of genes. These genes may themselves encode regulators oftranscription, signals, signal receptors, or modifiers of the cellular localization, stability, activity, or interactions with other molecules. While some effects of signal-receptor interactions can be transient, leading to reversible changes in cell state (and gene expression), during embryonic development activating and responding to a signal generally starts a cascade of effects that leads to irreversible changes, and the formation of altered differentiated states. Acell’s response to a signal can be variable, and influenced by the totality of the signals it receives and its past history.For example, a signal could lead to a decrease in the level of a receptor, or an increase in an inhibitory protein, making the cell unresponsive to the signal (a negative feedback effect) or more sensitive (a positive feedback effect) or could lead to a change in its response to a signal – different genes could be regulated as time goes by following the signal.Such emerging patterns of gene expression, based on signaling inputs, are the primary driver of embryonic development.
footnotes:
Not all genes are differentially expression, however – some genes, known as housekeeping genes, are expressed in essential all cells.
Hopefully it is clear what the term “expressed” means – namely that part of the gene is used to direct the synthesis of RNA (through the process of transcription (DNA-dependent, RNA polymerization).Some such RNAs (messenger or mRNAs) are used to direct the synthesis of a polypeptide through the process of translation (RNA-directed, amino acid polymerization) others do not encode polypeptides, such non-coding RNAs (ncRNAs) can play roles in a number of processes, from catalysis to the regulation of transcription, RNA stability, and translation.
Eggs are laid in water and are exposed to the sun; the pigmentation of the animal hemisphere is thought to protect the oocyte/zygote/early embryo’s DNA from photo-damage.
Literature cited
Chen et al., (2016). The ins (ide) and outs (ide) of asymmetric stem cell division. Current opinion in cell biology43, 1-6.
De Domenico et al., (2015). Molecular asymmetry in the 8-cell stage Xenopus tropicalis embryo described by single blastomere transcript sequencing. Developmental biology408, 252-268.
Gard & Klymkowsky. (1998). Intermediate filament organization during oogenesis and early development in the clawed frog, Xenopus laevis. In Intermediate filaments (ed. H. Herrmann & J. R. Harris), pp. 35-69. New York: Plenum.
Neumüller & Knoblich. (2009). Dividing cellular asymmetry: asymmetric cell division and its implications for stem cells and cancer. Genes & development23, 2675-2699.
Streit & Davis. (2016). Chromatin Diminution. In eLS: John Wiley & Sons Ltd, Chichester.
21st Century DEVO-2 In the first post in this series [link], I introduced the observation that single celled organisms can change their behaviors, often in response to social signals.They can respond to changing environments and can differentiate from one cellular state to the another. Differentiation involves changes in which sets of genes are expressed, which polypeptides and proteins are made [previous post], where the proteins end up within the cell, and which behaviors are displayed by the organism. Differentiation enables individuals to adapt to hostile conditions and to exploit various opportunities.
The ability of individuals to cooperate with one another, through processes such as quorum sensing, enables them to tune their responses so that they are appropriate and useful. Social interactions also makes it possible for them to produce behaviors that would be difficult or impossible for isolated individuals.Once individual organisms learn, evolutionarily, how to cooperate, new opportunities and challenges (cheaters) emerge. There are strategies that can enable an organism to adapt to a wider range of environments, or to become highly specialized to a specific environment,through the production of increasingly complex behaviors.As described previously, many of these cooperative strategies can be adopted by single celled organisms, but others require a level of multicellularity.Multicellularity can be transient – a pragmatic response to specific conditions, or it can be (if we ignore the short time that gametes exist as single cells) permanent, allowing the organism to develop the range of specialized cells types needed to build large, macroscopic organisms with complex and coordinated behaviors. In appears that various forms of multicellularity have arisen independently in a range of lineages (Bonner, 1998; Knoll, 2011). We can divide multicellularity into two distinct types, aggregative and clonal – which we will discuss in turn (1). Aggregative (transient) multicellularity:Once organisms had developed quorum sensing, they can monitor the density of related organisms in their environment and turn or (or off) specific genes (or sets of genes, necessary to produce a specific behavior.While there are many variants, one model for sucha behavior isa genetic toggle switch, in which a particular gene (or genes) can be switched on or off in response to environmental signals acting as allosteric regulators of transcription factor proteins (see Gardner et al., 2000).Here is an example of an activity (↓) that we will consider in class to assess our understanding of the molecular processes involved.
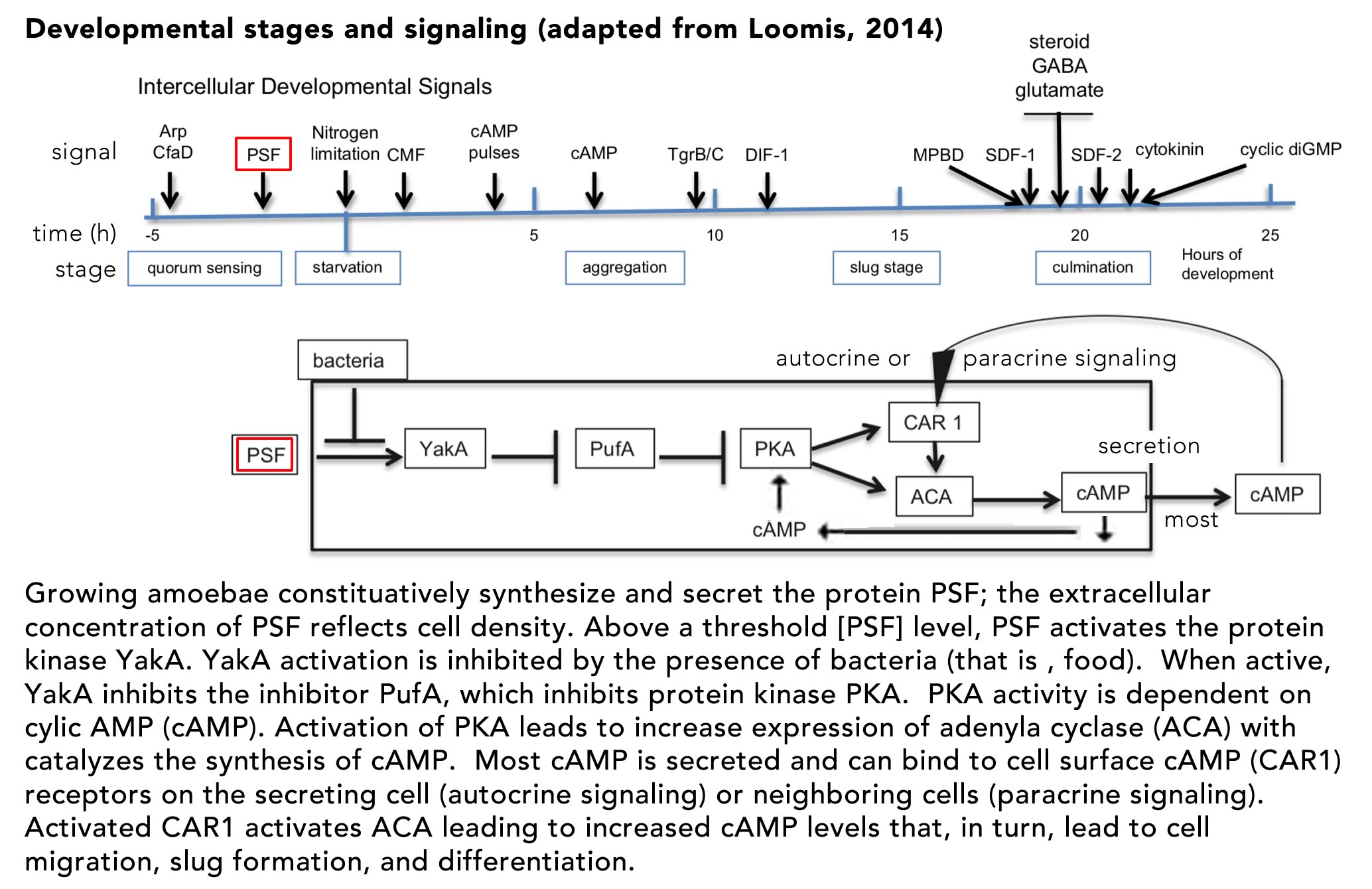
One outcome of such a signaling system is to provoke the directional migration of amoeba and their aggregation to form the transient multicellular “slug”.Such behaviors has been observedin a range of normally unicellular organisms (see Hillmann et al., 2018)(↓). The classic example isthe cellular slime mold Dictyostelium discoideum (Loomis, 2014).Under normal conditions, these
unicellular amoeboid eukaryotes migrate, eating bacteria and such. In this state, the range of an individual’s movement is restricted to short distances.However when conditions turn hostile, specifically a lack of necessary nitrogen compounds, there is a compelling reason to abandon one environment and migrate to another, more distant that a single-celled organism could reach. This is a behavior that depends upon the presence of a sufficient density (cells/unit volume) of cells that enables them to: 1) recognize one another’s presence (through quorum sensing), 2) find each other through directed (chemotactic) migration, and 3) form a multicellular slug that can go on to differentiate. Upon differentiation about 20% of the cells differentiate (and die), forming a stalk that lifts the other ~80% of the cells into the air.These non-stalk cells (the survivors) differentiate into spore (resistant to drying out) cells that are released into the air where they can be carried to new locations, establishing new populations.
The process of cellular differentiation in D. discoideum has been worked out in molecular detail and involves two distinct signaling systems: the secreted pre-starvation factor (PSF) protein and cyclic AMP (cAMP).PSF is a quorum signaling protein that also serves to activate the cell aggregation and differentiation program (FIG. ↓)
If bacteria, that is food, are present, the activity of PSF is inhibited andcells remain in their single cell state. The key regulator of downstream aggregation and differentiation is the cAMP-dependent protein kinase PKA.In the unicellular state, PKA activity is inhibited by PufA.As PSF increases, while food levels decrease, YakA activity increases, inactivating PufA, leading to increased PKA activity.Active PKA induces the synthesis of two downstream proteins, adenylate cyclase (ACA) and the cAMP receptor (CAR1). ACA catalyzes cAMP synthesis, much of which is secreted from the cell as a signaling molecule. The membrane-bound CAR1 protein acts as a receptor for autocrine (on the cAMP secreting cell) and paracrine (on neighboring cells) signaling.The binding of cAMP to CAR1 leads to further activation of PKA, increasing cAMP synthesis and secretion – a positive feed-back loop. As cAMP levels increase, downstream genes are activated (and inhibited) leading cells to migrate toward one another, their adhesion to form a slug.Once the slug forms and migrates to an appropriate site, the process of differentiation (and death) leading to stalk and spore formation begins. The fates of the aggregated cells is determined stochastically, but social cheaters can arise. Mutations can lead to individuals that avoid becoming stalk cells.In the long run, if all individuals were to become cheaters, it would be impossible to form a stalk, so the purpose of social cooperation would be impossible to achieve.In the face of environmental variation, populations invaded by cheaters are more likely to become extinct.For our purposes the various defenses against cheaters are best left to other courses (see here if interested Strassmann et al., 2000).
Clonal (permanent) multicellularity:The type of multicellularity that most developmental biology courses focus on is what is termed clonal multicellularity – the organism is a clone of an original cell, the zygote, a diploid cell produced by the fusion of sperm and egg, haploid cells formed through the process of meiosis (2).It is during meiosis that most basic genetic processes occur, that is the recombination between maternal and paternal chromosomes leading to the shuffling of alleles along a chromosome, and the independent segregation of chromosomes to form haploid gametes, gametes that are genetically distinct from those present in either parent. Once the zygote forms, subsequent cell divisions involve mitosis, with only a subset of differentiated cells, the cells of the germ line, capable of entering meiosis.
Non-germ line, that is somatic cells, grow and divide. They interact with one another directly and through various signaling processes to produce cells with distinct patterns of gene expression, and so differentiated behaviors.A key difference from a unicellular organism, is that the cells will (largely) stay attached to one another, or to extracellular matrix materials secreted by themselves and their neighbors.The result is ensembles of cells displaying different specializations and behaviors.As such cellular colonies get larger, they face a number of physical constraints – for example, cells are open non-equilibrium systems, to maintain themselves and to grow and reproduce, they need to import matter and energy from the external world. Cells also produce a range of, often toxic, waste products that need to be removed.As the cluster of zygote-derived cells grows larger, and includes more and more cells, some cells will become internal and so cut off from necessary resources. While diffusive processes are often adequate when a cell is bathed in an aqueous solution, they are inadequate for a cell in the interior of a large cell aggregate (3).The limits of diffusive processes necessitate other strategies for resource delivery and waste removal; this includes the formation of tubular vascular systems (such as capillaries, arteries, veins) and contractile systems (hearts and such) to pump fluids through these vessels, as well as cells specialized to process and transport a range of nutrients (such as blood cells).As organisms get larger, their movements require contractile machines (muscle, cartilage, tendons, bones, etc) driving tails, fins, legs, wings, etc. The coordination of such motile systems involves neurons, ganglia, and brains. There is also a need to establish barriers between the insides of an organism and the outside world (skin, pulmonary, and gastrointestinal linings) and the need to protect the interior environment from invading pathogens (the immune system).The process of developing these various systems depends upon controlling patterns of cell growth, division, and specialization (consider the formation of an arm), as well as the controlled elimination of cells (apoptosis), important in morphogenesis (forming fingers from paddle-shaped appendages), the maturation of the immune system (eliminating cells that react against self), and the wiring up, and adaptation of the nervous system. Such changes are analogous to those involved in aggregative multicellularity.
Origins of multicellularity:While aggregative multicellularity involves an extension of quorum sensing and social cooperation between genetically distinct, but related individuals, we can wonder whether similar drivers are responsible for clonal multicellularity.There are a number of imaginable adaptive (evolutionary) drivers but two spring to mind: a way to avoid predators by getting bigger than the predators and as a way to produce varied structures needed to exploit various ecological niches and life styles. An example of the first type of driver of multicellularity is offered by the studies of Boraas et al(1998). They cultured the unicellular green alga Chlorella vulgaris, together with a unicellular predator, the phagotrophic flagellated protist Ochromonas vallescia. After less than 100 generations (cell divisions), they observed the appearance of multicellular, and presumable inedible (or at least less easily edible), forms. Once selected, this trait appears to be stable, such that “colonies retained the eight-celled form indefinitely in continuous culture”.To my knowledge, the genetic basis for this multicellularity remains to be determined.
Cell Differentiation:One feature of simple colonial organisms is that when dissociated into individual cells, each cell is capable of regenerating a new organism. The presence of multiple (closely related) cells in a single colony opens up the possibility of social interactions; this is distinct from the case in aggregative multicellularity, where social cooperation came first. Social cooperation within a clonal metazoan means that most cells “give up” their ability to reproduce a new organism (a process involving meiosis). Such irreversible social interactions mark the transition from a colonial organism to a true multicellular organism. As social integration increases, cells can differentiate so as to perform increasingly specialized functions, functions incompatible with cell division. Think for a moment about a human neuron or skeletal muscle cell – in both cases, cell division is no longer possible (apparently). Nevertheless, the normal functioning of such cells enhances the reproductive success of the organism as a whole – a classic example of inclusive fitness (remember heterocysts?)Modern techniques of single cell sequencing and data analysis have now been employed to map this process of cellular differentiation in increasingly great detail, observations that will inform our later discussions (see Briggs et al., 2018 and future posts). In contrast, the unregulated growth of a cancer cell is an example of an asocial behavior, an asocial behavior that is ultimately futile, except in those rare cases (four known at this point) in which a cancer cell can move from one organism to another (Ujvari et al., 2016).
Unicellular affordances for multicellularity:When considering the design of a developmental biology course, we are faced with the diversity of living organisms – the basic observation that Darwin, Wallace, their progenitors and disciplinary descendants set out to solve. After all there are many millions of different types of organisms; among the multicellular eukaryotes, there are six major group : the ascomycetes and basidiomycetes fungi, the florideophyte red algae, laminarialean brown algae, embryophytic land plants and animals
(Knoll, 2011 ↑).Our focus will be on animals. “All members of Animalia are multicellular, and all are heterotrophs (i.e., they rely directly or indirectly on other organisms for their nourishment). Most ingest food and digest it in an internal cavity.” [Mayer link].From a macroscopic perspective, most animals have (or had at one time during their development) an anterior to posterior, that is head to tail, axis. Those that can crawl, swim, walk, or fly typically have a dorsal-ventral or back to belly axis, and some have a left-right axis as well.
But to be clear, a discussion of the various types of animals is well beyond the scope of any introductory course in developmental biology, in part because there are 35 (assuming no more are discovered) different “types” (phyla) of animals – nicely illustrated at this website [BBC: 35 types of animals, most of whom are really weird)].So again, our primary focus will be on one group, the vertebrates – humans are members of this group.We will also consider experimental insights derived from studies of various “model” systems, including organisms from another metazoan group, theecdysozoa (organisms that shed their outer layer as they grow bigger), a group that includes fruit flies and nematode worms.
My goal will be to ignore most of the specialized terminology found in the scholarly literature, which can rapidly turn a biology course into a vocabulary lesson and that add little to understanding of basic processes relevant to a general understanding of developmental processes (and relevant to human biology, medicine, and biotechnology). This approach is made possible by the discovery that the basic processes associated with animal (and metazoan) development are conserved. In this light, no observation has been more impactful than the discovery that the nature and organization of the genes involved in specifying the head to tail axes of the fruit fly and vertebrates (such as the mouse and human) is extremely similar in terms of genomic organization and function (Lappin et al., 2006 ↓), an observation that we will return to repeatedly.Such molecular similarities extend to cell-cell and cell-matrix adhesion systems, systems that release and respond to various signaling molecules, controlling cell behavior and gene expression, and reflects the evolutionary conservation and the common ancestry of all animals (Brunet and King, 2017; Knoll, 2011).
What can we know about the common ancestor of the animals?Early on in the history of comparative cellular anatomy, the striking structural similarities between the feeding system of choanoflagellate protozoans, a motile (microtubule-based) flagellum a surrounded by a “collar”of microfilament-based microvilli) and a structurally similar organelle in a range of multicellular organisms led to the suggestion that choanoflagellates and animals shared a common ancestor.The advent of genomic sequencing and analysis has only strengthened this hypothesis, namely that choanoflagellates and animals form a unified evolutionary clade, the ‘Choanozoa’(see tree↑ above)(Brunet and King, 2017).Moreover, “many genes required for animal multicellularity (e.g., tyrosine kinases, cadherins, integrins, and extracellular matrix domains) evolved before animal origins”.The implications is that the Choanozoan ancestor was predisposed to exploit some of the early opportunities offered by clonal multicellularity. These pre-existing affordances, together with newly arising genes and proteins (Long et al., 2013) were exploited in multiple lineages in the generation of multicellular organisms (see Knoll, 2011).
Basically to understand what happened next, some ~600 million years ago or so, we will approach the various processes involved in the shaping of animal development.Because all types of developmental processes, including the unicellular to colonial transition, involve changes in gene expression, we will begin with the factors involved in the regulation of gene expression.
Footnotes: 1). Please excuse the inclusive plural, but it seems appropriate in the context of what I hope will be a highly interactive course.
2). I will explicitly ignore variants as (largely) distractions, better suited for more highly specialized courses. 3). We will return to this problem when (late in the course, I think) we will discuss the properties of induced pluripotent stem cell (iPSC) derived organoids.
Literature cited: Bonner, J. T. (1998). The origins of multicellularity. Integrative Biology: Issues, News, and Reviews: Published in Association with The Society for Integrative and Comparative Biology 1, 27-36.
Boraas, M. E., Seale, D. B. and Boxhorn, J. E. (1998). Phagotrophy by a flagellate selects for colonial prey: a possible origin of multicellularity. Evolutionary Ecology 12, 153-164.
Briggs, J. A., Weinreb, C., Wagner, D. E., Megason, S., Peshkin, L., Kirschner, M. W. and Klein, A. M. (2018). The dynamics of gene expression in vertebrate embryogenesis at single-cell resolution. Science 360, eaar5780.
Brunet, T. and King, N. (2017). The origin of animal multicellularity and cell differentiation. Developmental cell 43, 124-140.
Gardner, T. S., Cantor, C. R. and Collins, J. J. (2000). Construction of a genetic toggle switch in Escherichia coli. Nature 403, 339-342.
Hillmann, F., Forbes, G., Novohradská, S., Ferling, I., Riege, K., Groth, M., Westermann, M., Marz, M., Spaller, T. and Winckler, T. (2018). Multiple roots of fruiting body formation in Amoebozoa. Genome biology and evolution 10, 591-606.
Knoll, A. H. (2011). The multiple origins of complex multicellularity. Annual Review of Earth and Planetary Sciences 39, 217-239.
Lappin, T. R., Grier, D. G., Thompson, A. and Halliday, H. L. (2006). HOX genes: seductive science, mysterious mechanisms. The Ulster medical journal 75, 23.
Long, M., VanKuren, N. W., Chen, S. and Vibranovski, M. D. (2013). New gene evolution: little did we know. Annual review of genetics 47, 307-333.
Loomis, W. F. (2014). Cell signaling during development of Dictyostelium. Developmental biology 391, 1-16.
Strassmann, J. E., Zhu, Y. and Queller, D. C. (2000). Altruism and social cheating in the social amoeba Dictyostelium discoideum. Nature 408, 965-967.
Ujvari, B., Gatenby, R. A. and Thomas, F. (2016). Transmissible cancers, are they more common than thought? Evolutionary applications 9, 633-634.